Octopus Semantic Web
Lisa Park has developed Octopus CIP (Cloud Interactive Platform) , to support interactive, near real-time data analysis using semantic structures of Octopus processing models.
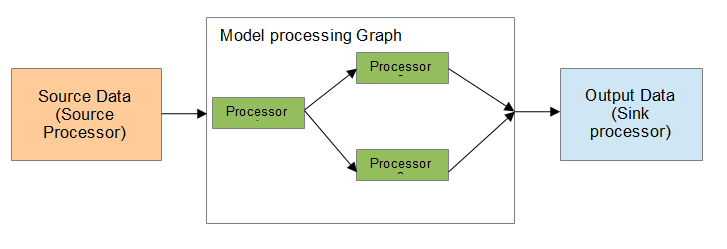
All data in Octopus CIP are processed using Octopus Models. Each Octopus model is defined as a triple (containing three elements):
- Model’s Source Data, connection to which is provided by a special type of processor - the Source Processor;
- Model’s processing Graph is a collection of interconnected processors. These processors are graph nodes and connections between them are graph edges;
- Model’s Output Data, connection to which is provided by the Sink Processor.
Octopus models are stored in the Object Database (currently, it’s an Open Source version of db4o Object Database).
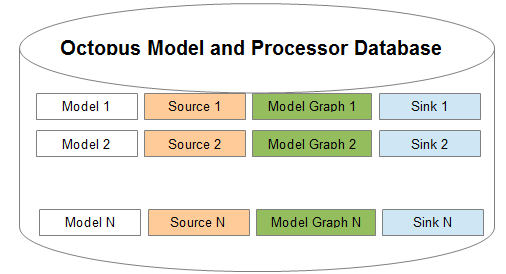
All models in the Object Data Store are uniquely identified. There are at least two benefits that come with using database as a way to store Octopus models:
- Models become accessible from the Internet (with appropriate credentials);
- Models can be searched for by using query language very similar to standard SQL.
Below are examples of some relations that can be defined on Octopus models:
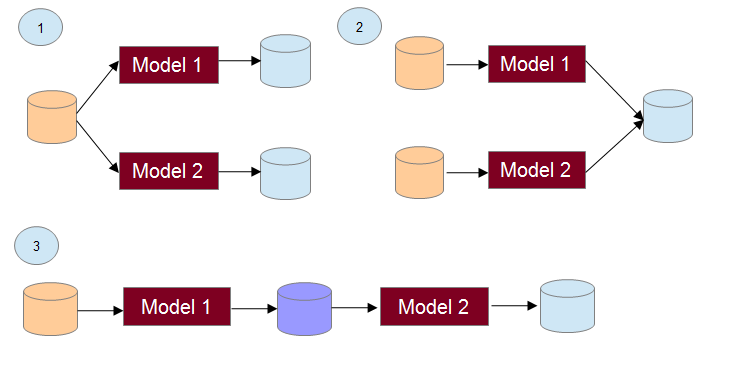
The first example presents two models related by sharing the same data source (in case of a database, the actual query may be different, but the database and even the table may be the same). The two models represent two different points of views on the same object presented in a specified database (or a table, or a spreadsheet).
The second example shows relationship between models based on result (output) data. This kind of association can be linked to relations by subject or solution. In fact, the two models can represent different approaches to solving the same problem.
The third example presents sequential execution of the models when output of the first one is used as a source data for the next one.
Octopus models are built on sharable set of standard processors. All processors are uniquely identified and are stored in the same Object Database. This fact allows us to use Model processing Graph as an additional parameter in the query, while searching for related models.
One of the biggest concerns of “Big data” is combinatorial complexity of any analysis being performed on this data. A sizable team of data scientists can help a little in this case, but it also can create a new set of problems. Each of the team members is a scientist, meaning that each one has his or hers own view on the subject and the substance of analysis. Subconsciously, each of them will look for evidence that justifies their position. To eliminate this bias, we need to integrate investigative efforts of each team member in a coherent solution. In Octopus CIP, this is as simple as redirecting the output of each model to the same data resource.
There are a lot of similarities in concept and implementation between Octopus CIP and Semantic Web. These fundamental relationships between Semantic Web and Octopus CIP expand capabilities of data analysis and leads us to the natural integration with the wealth of information presented on the web, including all kinds of social data.
The following is a summary of features that integration of Octopus CIP and Semantic Web can bring to data analysis:
- Octopus CIP adds dynamic component to the explicitly defined static structure of semantic web, presented by RDF – Resource Description Framework.
- Octopus CIP dynamic structure represented by a set of models, reflects time and cause-and-effect related correlations among semantic web nodes.
- Octopus CIP is an event processing framework that evaluates and processes semantic web’s dynamic structure represented by Octopus models.
- Octopus CIP performs such processing in real time. It can also evaluate the correctness of the dynamic structure by comparing predicted and factual configurations of semantic web. Octopus models can recalculate and readjust semantic web’s dynamic structure to correct output for the following iterations of applied processing models.
- Using dynamic component of semantic web, Octopus CIP makes it possible to connect different semantic web’s nodes, even when they are not immediately related.
Neo4j is arguably the most known and widely used Graph database. Neo4j and Octopus CIP both share very similar ideologies in their approach to data processing. This similarity helped us to implement simple yet powerful set of processors that we are using to build a library of specialized models to manage Octopus Semantic Web.
Meta-data analysis is fundamentally paramount aspect of the way Octopus CIP operates. It was rooted in this idea from the start. Octopus uses semantic, independent relations methodology to describe its Meta information.
Octopus was designed and developed as technology destined to live in the Cloud, where it could engage a large community of users generating meta-data.
Meta-data generation is the joint product resulting from the activities of a multitude of independent users, concerned with their part of meta-data structure only. Neo4j provides us with possibility to naturally combine all these meta-data structures into a coherent semantic web.
This resulting Meta-data structure can serve as a starting point, from which data analysis on Big Data can be performed.
- START root=node(*) RETURN root; - will return all saved in Neo4j database nodes;
- START nodes=node(nodeId) RETURN nodes; - will return a node with a specified nodeId;
- START nodes=node(*) MATCH (nodes) - [CLUSTER] -> (models) RETURN nodes; - returns all models connected to the ROOT cluster node;
- START nodes=node(*) MATCH (nodes) - [SOLUTION] -> (models) RETURN nodes; - returns all nodes related to the ROOT Solution of a Constraint optimization task (all products, machines and technological steps);
- START nodes=node(53) MATCH (nodes) - [SOLUTION] - (items) WHERE nodes.productId = 'prod01' RETURN nodes; - returns all products and machines that are using technology step represented by node 53.